《Externalization in LLM Agents》:LLM Agent 的认知外部化
这篇综述把 memory、skills、protocols 和 harness engineering 统一到一个视角里:Agent 的进步越来越像是在模型外部重写任务,而不只是让模型权重更强。
很多关于 Agent 的讨论,会自然滑向模型排行榜。
哪个模型更聪明,哪个推理更强,哪个上下文窗口更长,这些当然重要。但这篇 《Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering》 提醒我们,Agent 的另一条主线不在模型内部,而在模型外部。
它问的不是“模型还能学会什么”,而是:
哪些原本压在模型身上的认知负担,可以被搬到外部结构里?
这就是论文用 externalization 这个词的原因。它不是给模型外挂几个组件,也不是把工具列表塞进 prompt。它更像人类使用纸、地图、日历和计算机:外部物件没有让大脑本身突然变大,但它改变了任务的形状。记忆变成识别,心算变成操作符号,临场发挥变成遵循流程。
LLM Agent 也是这样。
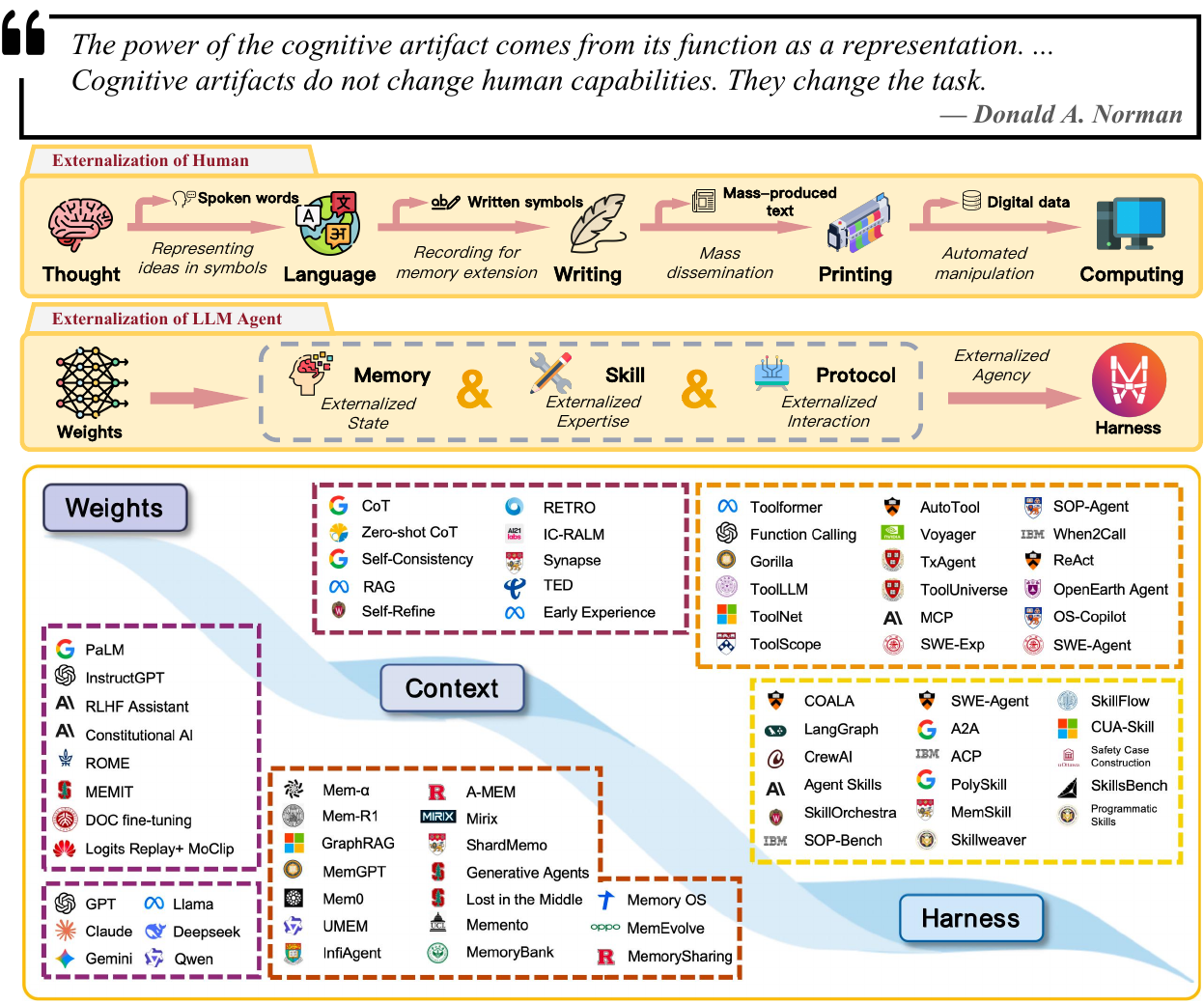
Figure 1, from Zhou et al., arXiv:2604.08224, CC BY-NC-SA 4.0, format-converted for web display, content unchanged.
一篇综述真正有价值的地方
这篇论文不是提出一个新模型,也不是发布一个新 benchmark。它是一篇综述,价值在于给正在发生的工程迁移命名。
过去我们习惯把能力理解成权重里的东西:更大参数量、更好预训练、更强对齐。后来,能力越来越多地通过上下文被组织起来:prompt、few-shot 示例、RAG、chain-of-thought、工具说明。再往后,真正复杂的 Agent 系统开始依赖更厚的运行时:文件系统、记忆库、技能库、工具协议、沙箱、审批、日志、评估器、子 Agent 编排。
论文把这条线概括成:
weights → context → harness
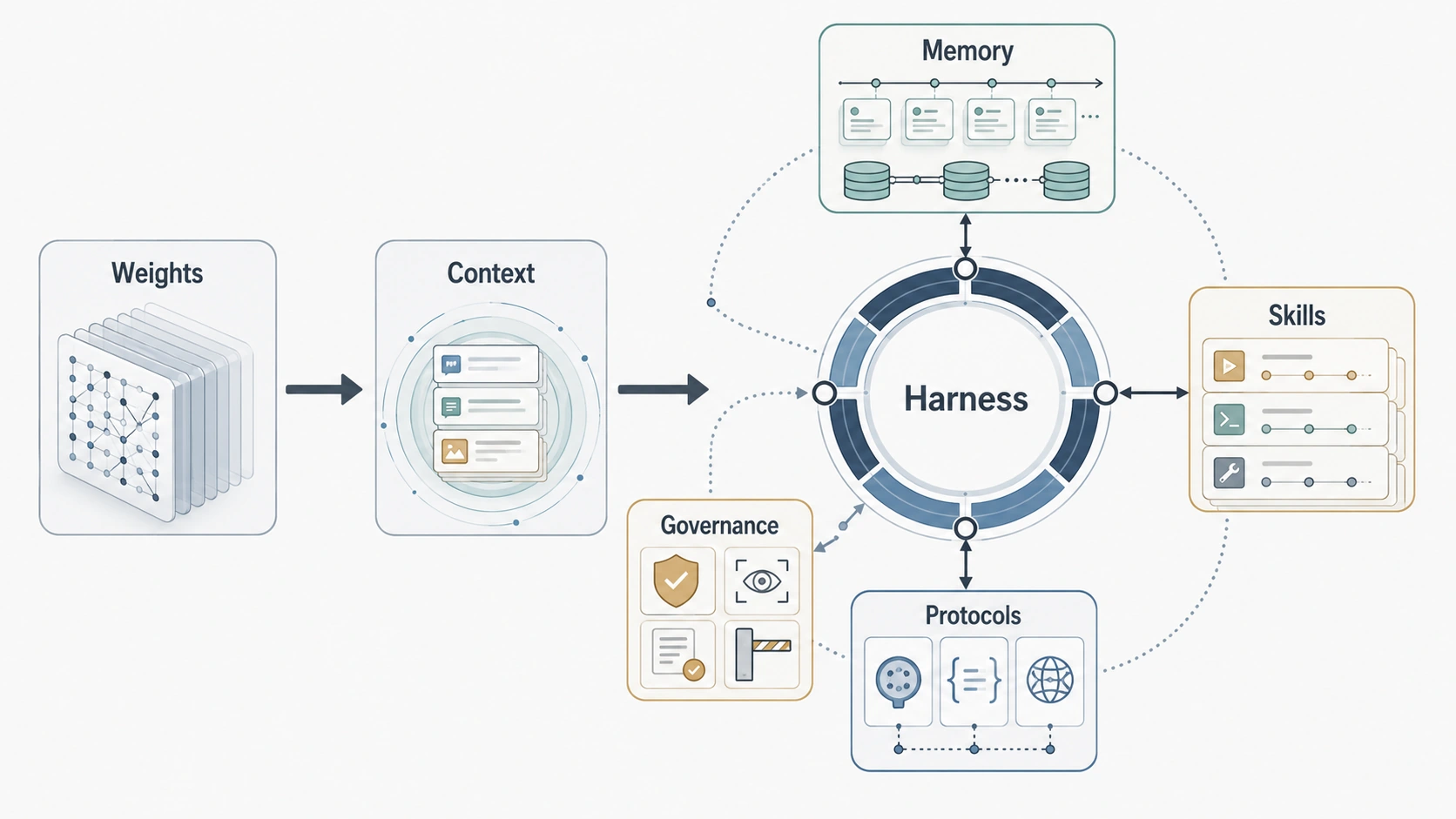
这张图表达的是一条工程主线:能力不是只放在模型权重里。早期系统更多依赖 weights;上下文工程成熟之后,任务可以在 context 里被临时组织;到了 Agent,长期可靠性必须落到 harness。Memory 保存状态,skills 沉淀流程,protocols 规范工具和 Agent 之间的交互,governance 处理权限、审计和失败恢复。
因此,Agent 的关键问题不只是模型有多强,而是外部运行环境能不能把任务稳定地表示、约束和恢复。
Memory:把时间搬到模型外面
最容易理解的外部化是 memory。
如果只依赖上下文窗口,Agent 每次运行都像带着一段临时工作记忆。窗口再长,也会遇到选择问题:什么该放进去,什么该忘掉,什么信息只是噪音。更关键的是,上下文本身是一次性的。任务结束之后,如果没有外部状态,很多经验就消失了。
Memory 系统把这个问题从“模型能不能凭空回忆”改写成“模型能不能在需要时识别并使用被检索出来的状态”。这和论文借用的 cognitive artifacts 视角是一致的:购物清单不增强生物记忆,它把回忆任务变成识别任务。
对 Agent 来说,外部 memory 可以保存用户偏好、项目约定、历史决策、失败轨迹、领域事实。真正困难的地方不只是存,而是选择。一个好的 memory 系统必须决定哪些状态值得沉淀,什么时候检索,检索多少,如何压缩,如何避免旧状态污染新判断。
所以 memory 不是“更长上下文”的低配替代,而是时间维度上的基础设施。
Skills:把过程搬到模型外面
第二个外部化是 skills。
这里的 skill 不是“模型会用某个工具”,而是一段可复用的过程性知识。它可能包含操作步骤、判断启发式、边界条件、失败恢复方式和安全约束。一个成熟的 skill 告诉 Agent:这类任务通常怎么做,先看什么,什么时候停止,什么时候升级给人。
这和工具调用不是同一层抽象。工具提供动作,protocol 规定动作如何被描述和调用,skill 则封装“如何把这些动作组织成一件事”。
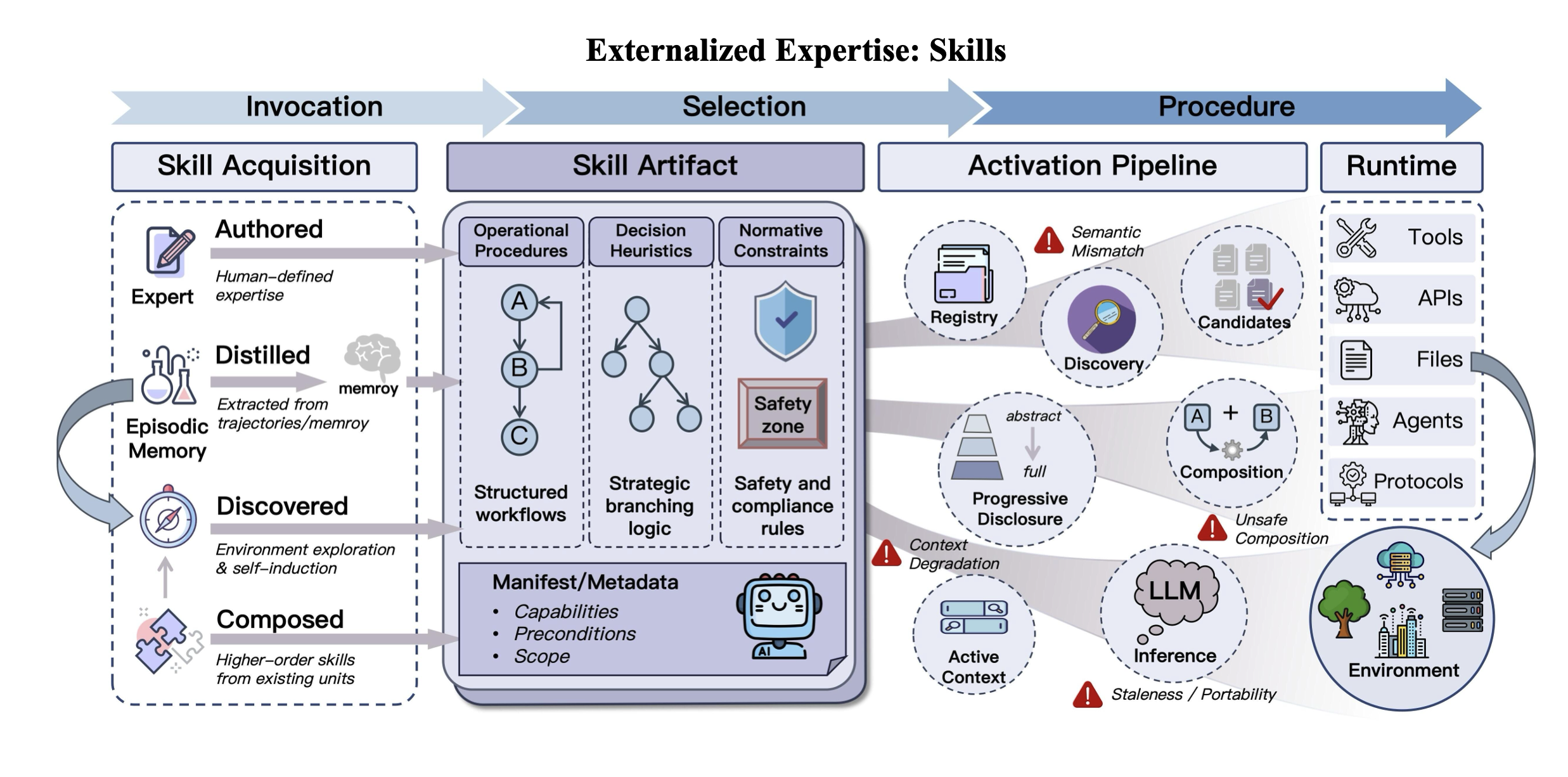
Figure 5, from Zhou et al., arXiv:2604.08224, CC BY-NC-SA 4.0, reproduced unchanged.
这点对软件工程 Agent 尤其明显。
一个模型可能知道如何修改代码、运行测试、读错误日志、写 PR 描述。但稳定完成任务,通常还需要很多本地流程:先读哪些文件,如何保护用户改动,什么时候用 rg,什么时候跑全量测试,如何处理已有暂存区,哪些命令不能乱用。
如果这些都留给模型每次现场推导,Agent 的行为就容易发生漂移。把它们外部化成 skill,任务就不再是“临场发明流程”,而是“选择并执行已验证的流程”。
这也是 skills 在 Agent 工程里容易被低估的原因。它不炫,但它直接降低方差。
Protocols:把交互秩序搬到模型外面
第三个外部化是 protocols。
没有 protocol 的 Agent 交互,本质上是自由文本协商。模型说自己要调用工具,工具返回一段文本,另一个 Agent 再猜这段文本代表什么。小 demo 里这可以工作,生产系统里会很脆。
Protocol 的作用,是把含糊交互变成机器可读的契约。工具如何发现,参数如何声明,权限如何表达,错误如何返回,Agent 之间如何委托,用户审批如何进入流程,这些都不应该全靠 prompt 约定。
这类外部化的价值不只是互操作性。它还提供治理入口。只要交互是结构化的,系统就能做校验、审计、限权、回放和监控。自由文本很灵活,但也很难治理。
Harness:不是包装器,而是认知环境
论文最重要的收束,是把 memory、skills 和 protocols 放进 harness engineering 里。
Harness 不是薄薄一层 wrapper。它是 Agent 真正运行的认知环境:控制循环、上下文预算、工具权限、沙箱隔离、人工审批、日志观察、失败恢复、子 Agent 编排,都在这里发生。
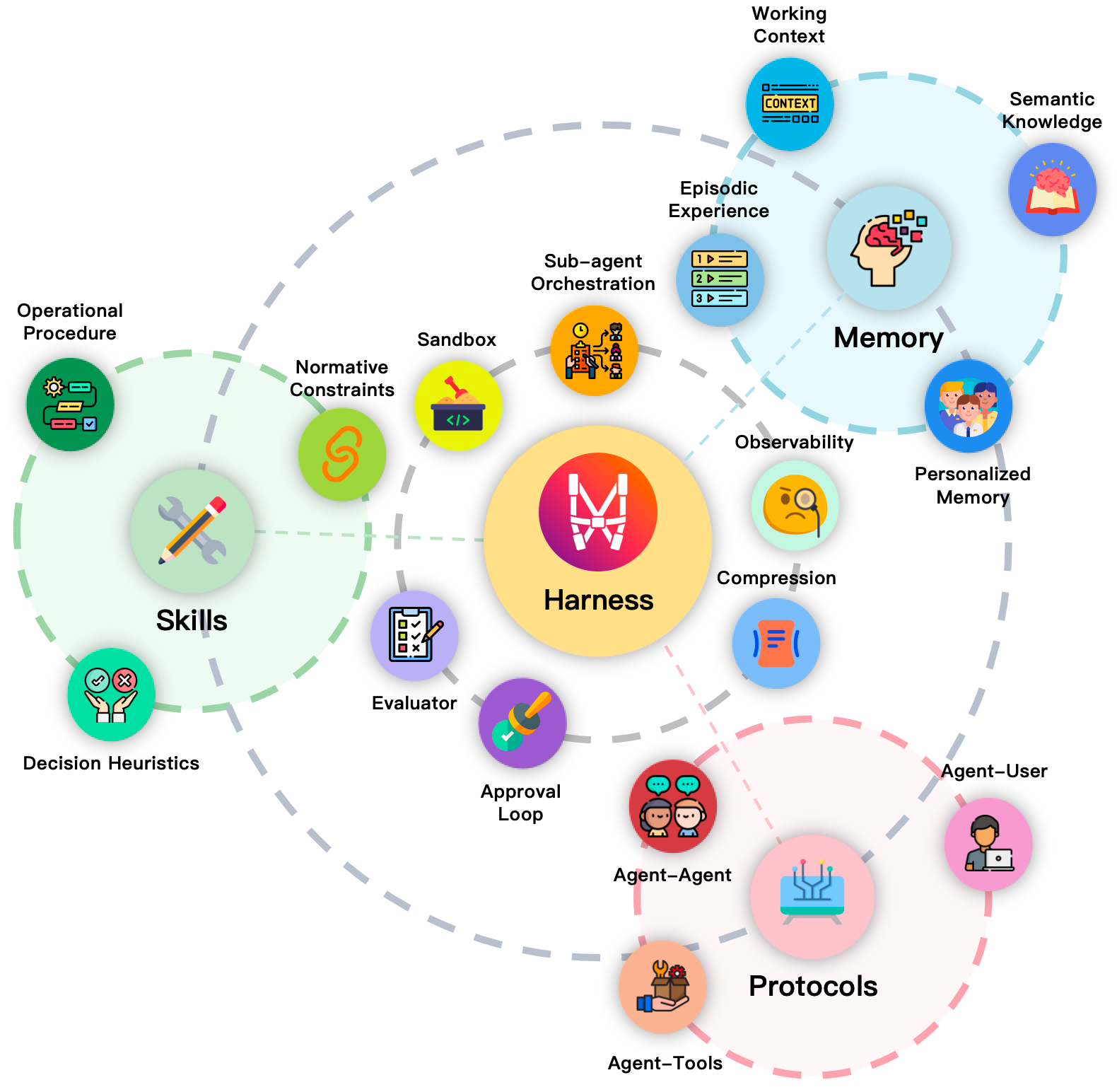
Figure 3, from Zhou et al., arXiv:2604.08224, CC BY-NC-SA 4.0, reproduced unchanged.
这里有一个容易误解的地方:harness 不是在 memory、skills、protocols 之外再加一个模块。它更像承载这些外部化模块的运行时。Memory 提供状态,skills 提供过程,protocols 提供交互结构,harness 决定它们什么时候被调用、如何互相影响、怎样被约束。
这也解释了为什么现代 Agent 看起来越来越像小型操作系统。它们不只是“一个模型加一串工具”,而是有资源、有权限、有生命周期、有日志、有策略的执行环境。
能力边界在移动
这篇论文最有用的地方,是它改变了“能力在哪里”的问题。
如果能力只在权重里,那么改进 Agent 的主要方式就是换模型、微调模型、继续训练模型。如果能力也在上下文里,那么 prompt、检索和工具说明就成为工程主战场。如果能力进一步进入 harness,那么系统设计本身就变成能力的一部分。
这不是在贬低模型。相反,越强的模型,越值得被放进更好的外部结构里。因为强模型擅长综合、判断、泛化,但它仍然不天然擅长稳定记忆、重复流程、权限治理、长期状态和跨系统协调。
外部化不是作弊。它是工程上承认边界,然后重写任务。
一个好的 Agent 系统,不是让模型每次都从零开始“想办法”。它会把可沉淀的状态沉淀成 memory,把可复用的过程沉淀成 skills,把可治理的交互沉淀成 protocols,再用 harness 把它们组织成可运行的环境。
也要警惕外部化的代价
论文的框架很漂亮,但不能把外部化理解成无成本扩展。
Memory 会带来陈旧状态、隐私边界和检索污染。Skills 会带来过时流程、错误复用和上下文竞争。Protocols 会带来标准碎片化和接口锁定。Harness 会带来系统复杂度:越多审批、日志、沙箱、策略和子流程,越需要工程纪律。
还有一个评估问题:如果 Agent 的能力分布在模型和外部基础设施之间,我们到底在评测什么?同一个模型,放进不同 harness,表现可能完全不同。那排行榜里的“模型能力”和产品里的“Agent 能力”就不再是同一件事。
这正是论文的位置。它不是说外部化解决一切,而是把问题放到正确的位置:Agent 的可靠性来自模型和环境的共同设计。
实用判断
这篇综述的钉子句是:Agent 进步的一条主线,是把认知负担从模型权重迁移到可检查、可复用、可治理的外部结构。
这不是说模型不重要。模型仍然决定理解、规划和生成的上限。但当 Agent 真正进入长期任务,可靠性不可能只靠一次次现场推理撑住。状态要能保存,流程要能复用,工具调用要有协议,权限和失败要能被 harness 接住。
外部化的本质,是把任务从“让模型每次想明白”改成“让系统把可沉淀的东西留下来”。Memory 保存时间,skills 保存过程,protocols 保存交互秩序,governance 保存边界,harness 把它们组织成运行环境。
下次看一个 Agent 系统,不要只问它用了哪个模型。先问它把什么认知负担搬到了外部,哪些外部结构可检查、可更新、可回滚。这个问题比模型名更接近系统的真实能力。
评论