《AutoCodeBench》:当大语言模型自动生成代码基准
AutoCodeBench 论文里,为什么 Elixir 这一语言列值得注意,以及它如何引出自动生成多语言代码 benchmark 的难度等价讨论
代码评测的第一性问题不是谁排第一,而是题目从哪里来。只要 benchmark 由模型生成、翻译、过滤,评测就不再只是“模型答题”,也是“模型出题系统”的产物。
《AutoCodeBench》 真正值得拆的地方,是自动生成多语言代码 benchmark 时,语言之间的“难”是否等价。Elixir 这一列之所以值得看,不是因为它能证明大模型最擅长 Elixir,而是因为它暴露了评测生成流程里的结构性变量。
先说这张排名表在讲什么
先看论文里的原始表格:
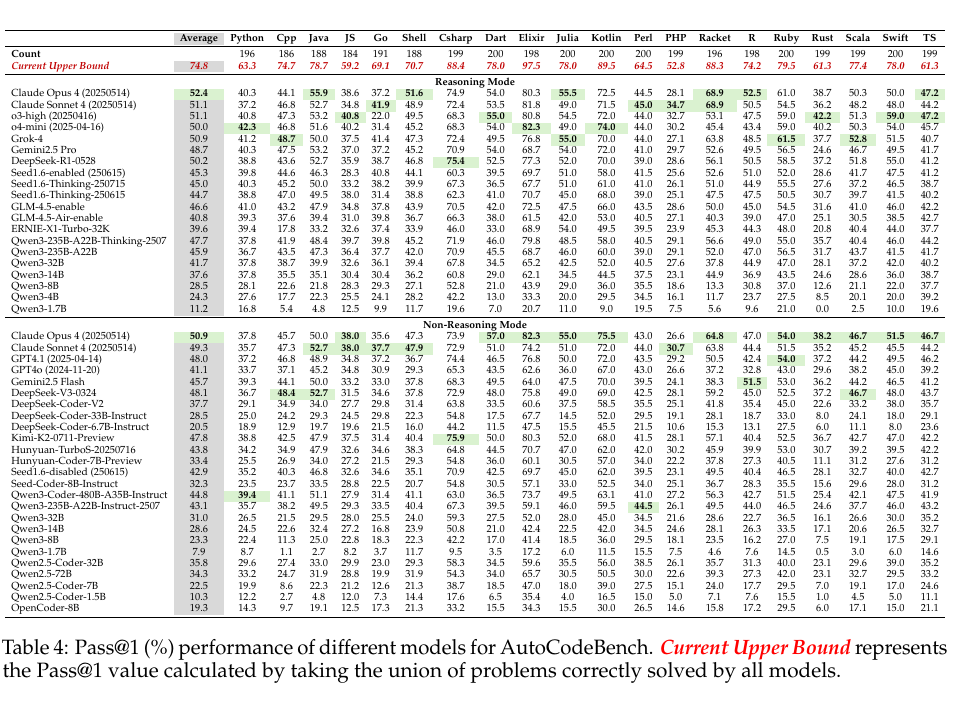
在原文 Table 4 里,每一行是一家参评大模型,每一列是一种编程语言。
交叉处那个数字表示:把这一语言的题交给这个模型,只看它第一次交出的答案,最后有多少题能一次通过测试。论文把这个指标记作 Pass@1。这里的 @1 可以直接理解成“只给一次机会”。
最顶上有一行特殊的,叫 Current Upper Bound。它不属于任何一个模型,而是把所有模型解对的题目取并集之后算出来的通过率。只要某道题被任意一个参评模型做对,它就进入这个上界。论文表注明确写了这一点。
Elixir 共 198 道题,Current Upper Bound 是 97.5。粗略折算,约 193 道 Elixir 题至少被一个模型解对。同一行里,Kotlin 是 89.5,C# 是 88.4,Racket 是 88.3,Python 是 63.3。
这里有个很容易踩的坑:不能把 Elixir 97.5 和 Python 63.3 直接写成“Elixir 比 Python 更适合大模型”。
这不是一个严谨结论。
因为不同语言的题目来源不同,生成方式不同,难度过滤效果也可能不同。直接拿语言列的数字去推导语言本体优劣,会把 benchmark 结果解释过头。
真正值得追问的是另一个问题:
同一批模型、同一套评测流程里,为什么 Elixir 这一语言列会稳定处在高位?
这不是单个模型的偶然
先排除一种解释:也许只是 Current Upper Bound 的统计特性。多个模型取并集,数字自然会变高。
那就看单个模型行。
Claude Opus 4 推理模式下,Elixir 是 80.3,C# 是 74.9,Kotlin 是 72.5。Claude Sonnet 4 非推理模式下,Elixir 是 74.2,C# 是 72.9,Kotlin 是 72.0。DeepSeek-R1-0528 推理模式下,Python 是 38.8,Elixir 是 77.3。
注意,这里比较的不是“Claude 和 Elixir”。Claude 是模型,Elixir 是语言,二者不在同一维度。
这里比较的是:
同一个模型,横向看它在不同编程语言上的表现。
从 Table 4 横着看,Elixir 经常出现在高分位置。它不是某一个模型的单点波动,而是多行模型结果里反复出现的语言列现象。
这把问题从总榜拉到了语言列。
题目是怎么来的
要理解这个现象,得回到 AutoCodeBench 的生成流程。
论文提出了一套叫 AutoCodeGen 的自动化流程:从 Stack-Edu 里的真实代码片段抽取种子,让模型把它演化成可独立运行的完整解法;再生成公开和私有测试输入;把解法和测试输入丢进多语言沙箱执行,得到真实输出;最后根据解法和测试函数反向生成题目描述。
这个设计的关键是:测试输出不是模型凭空写出来的,而是代码实际跑出来的。
这也是 AutoCodeBench 比“让模型直接编题编测试”更可信的地方。模型可以负责生成候选,沙箱负责给出事实。
但 20 种语言并不是完全用同一种方式生成的。
论文写得很清楚:Python、C++、Shell、Java、JavaScript、Go 这 6 种语言直接使用完整 AutoCodeGen 流程;其余 14 种语言虽然理论上也可以走同样流程,但由于数据资源有限、多样性不足,论文采用了近似语言翻译。Table 3 里,Elixir 的翻译路径是 Python → Elixir。
这就埋下了一个关键变量:
Elixir 题目很可能不是 Elixir 生态里的原生任务,而是从 Python 任务翻译过去的 Elixir 任务。
翻译本身不是问题。
问题在于:翻译之后,题目难度是否还能和其他语言保持等价?
难度过滤器的语言盲区
AutoCodeGen 有一个难度控制机制。
它用 DeepSeek-Coder-V2-Lite 对每道题采样 10 次,并用沙箱验证答案。10 次全对的题会被丢掉,因为论文认为这类题太简单,没有评测价值。
这个逻辑在热门语言上更容易成立。
如果过滤模型熟悉 Python、Java、C++,那么它能 10 次做对的题,大概率确实偏简单;它做不对的题,也更可能有一定难度。
但到了 Elixir 这样的低资源语言,情况会变复杂。
论文 Section 3.3 专门比较了热门语言和低资源语言。热门语言组选的是 Python、C++、Java、C#;低资源语言组选的是 Racket、Shell、Elixir、TypeScript。结果是,热门语言组里模型平均 Pass@1 差距较小,范围是 50.4 到 53.8;低资源语言组里模型差距更大,范围是 45.3 到 62.0。
论文随后给出了一个解释线索:顶级模型在低资源语言上表现显著更好,可能是因为 DeepSeek-Coder-V2-Lite 在低资源语言上的能力有限,难以过滤掉简单题。
这句话非常关键。
它没有直接说“Elixir 高分就是因为题简单”,但它提供了一个很合理的机制解释:
用于过滤简单题的模型,在低资源语言上可能不够强。因此,一些对强模型来说并不难的题,没有被同等强度地过滤掉。
这比“大模型最擅长 Elixir”解释得更稳。
Elixir 的高分,可能不是单纯来自模型对 Elixir 的语言掌握,而是同时受到三件事影响:
第一,题目来自 Python → Elixir 的近似翻译。
第二,难度过滤器在低资源语言上可能不如在热门语言上可靠。
第三,顶级模型和过滤模型之间的能力差,在低资源语言上被放大了。
这三件事叠在一起,就能解释为什么 Elixir 这一列会特别亮眼。
Lite 版本里还有一个侧面证据
AutoCodeBench 还有一个精简版,叫 AutoCodeBench-Lite。
Lite 的构造方式提供了一个侧面证据:论文先收集所有模型的解题结果,再按每道题被多少模型解出来排序;通过模型少于 2 个的题先丢掉,然后从剩下的题里按通过次数从低到高选择约 1,500 道。论文这样做,是为了保留那些“至少有模型能解,但仍有区分度”的题,让模型之间的差距更清晰。
在完整 AutoCodeBench 里,Elixir 有 198 道题。
到了 Lite 版本,Elixir 只剩 61 道。这个数量在 20 种语言里属于最低的一组,少于它的只有 JavaScript 的 57 和 PHP 的 60。
这个数字不能单独证明“Elixir 题都简单”。
因为题目没有进入 Lite,可能有两种原因:一种是太少模型能解,被第一步丢掉;另一种是太多模型能解,在按通过次数从低到高截取时排到了后面。
但结合 Elixir 的 Current Upper Bound 高达 97.5,以及很多单模型行里 Elixir 得分靠前,这个 Lite 数量变化至少提供了一个侧面信号:
完整 Elixir 题集的难度分布,很可能和其他语言不完全等价。
这才是重点。
不是说 Elixir 题“有问题”,也不是说 AutoCodeBench“不可靠”。
而是说:当 benchmark 通过自动生成、近似翻译和模型过滤构造时,不同语言之间的难度分布会被生成流程影响。
还有一层更隐蔽的偏差
论文 Section 4.2 还讨论了模型偏差问题。
整个生成流程大量使用 DeepSeek 系列模型:DeepSeek-V3-0324 负责代码生成,DeepSeek-R1-0528 负责 Critic 质量审核。论文也承认,这可能对 DeepSeek 家族模型产生有利偏差。为了缓解这一点,作者在简单题过滤阶段使用 DeepSeek-Coder-V2-Lite,试图形成一种“push-and-pull”的平衡机制。
更关键的是,论文的量化分析显示,偏差并不是一句“谁出题谁占便宜”就能解释完。
在 Table 7 的阶段性结果里,Critic 过滤阶段确实让 DeepSeek-R1-0528 得到提升,但 o3 和 Gemini 2.5 Pro 的提升幅度反而比 DeepSeek-V3-0324 更大。论文最后的判断也很克制:自动流程可能给 DeepSeek 家族带来有利偏差,但影响较小。
这部分和 Elixir 不是同一个问题,但它们指向同一个核心:
自动化 benchmark 不是中立机器。
谁来生成题目,谁来审核题目,谁来过滤简单题,哪些语言是原生生成,哪些语言是翻译生成,都会在数据里留下痕迹。
最后,这些痕迹会安静地进入排行榜。
Elixir 97.5 到底说明了什么
它说明的不是“大模型最擅长 Elixir”。
也不应该被写成“AutoCodeBench 有问题”。
更准确的说法是:
AutoCodeBench 暴露了自动生成多语言 benchmark 的一个关键难题:语言之间的难度等价,远比表面上更难。
表面上看,20 种语言分布均衡,每种语言大约 200 道题。
但分布均衡不等于难度等价。
一道 Python 任务翻译成 Elixir 后,是否仍然代表 Elixir 生态里的真实任务?
过滤模型在 Python 上能筛掉简单题,在 Elixir 上是否也能筛得同样干净?
沙箱能验证代码输出,但题目描述、语言习惯、接口设计、标准库使用方式,是否也同样自然、同样公平?
这些问题都不会直接出现在总分里。
但 Elixir 这一列让它们浮了出来。
这篇论文真正值得写的地方
AutoCodeBench 的价值不只是给模型排了个名。
它更重要的贡献,是把 benchmark 生产方式往前推了一步:让模型生成题目,让沙箱验证输出,让 Critic 检查质量,再用采样过滤控制难度。论文也明确说,AutoCodeBench 包含 3,920 道题、37,777 个测试用例,覆盖 20 种编程语言,目标是构造更困难、更实用、更多语言覆盖的代码生成评测集。
这条路肯定会继续走下去。
因为代码评测有一个天然优势:代码可以执行。只要任务定义得足够清楚,就可以通过测试用例验证答案。相比写作、开放问答、复杂推理,代码任务更适合形成“生成—执行—验证—过滤”的闭环。
但 Elixir 这一列提醒我们:自动化不是免费的。
模型生成题目,会带入模型熟悉的问题结构。
模型翻译题目,会带入源语言的任务形状。
模型过滤难度,会受自己的语言能力限制。
沙箱可以验证执行结果,却不能保证题目在每种语言生态里都一样自然、一样公平。
所以,未来的代码评测不只要问哪个模型得分最高,还要问:
- 这套题是怎么来的?
- 哪些语言是原生生成,哪些语言是翻译生成?
- 难度过滤器在不同语言上的能力是否一致?
- 人工验证覆盖了哪些语言,又没有覆盖哪些语言?
论文里的人类验证只覆盖了 Python、C++、Java、JavaScript、Go、Shell 六种语言,准确率为 87.6%;Elixir 并不在这组人工验证语言里。这个细节也说明,对翻译生成语言的质量和难度分布,还需要更细的后续验证。
最后的结论
AutoCodeBench 的钉子句是:自动生成 benchmark 的难点不是出题,而是让不同语言里的“难”保持等价。
Elixir 在表里显眼,不能直接推出“大模型最擅长 Elixir”。benchmark 的生成、翻译、过滤、人类验证覆盖范围都会影响分数。尤其当题目由 Python 扩展到其他语言时,语言列的分数就混合了模型能力、翻译路径和难度筛选能力。
但正因为这些变量都摆在台面上,Elixir 这一列才值得继续追。它提醒我们,代码评测不是中立容器。任务从哪里来、怎样被改写、由谁过滤,都会进入最终分数。
下次看代码 benchmark,不要只问哪个模型 Pass@1 更高。先问题目供应链:原生生成还是翻译生成,难度过滤器在哪些语言上可靠,人工验证覆盖了哪些语言。一个 benchmark 只有先解释清楚题目如何存在,分数才有解释权。
评论