《AutoCodeBench》: LLM이 코드 벤치마크를 자동 생성할 때
AutoCodeBench에서 왜 Elixir 열이 눈여겨볼 만한지, 그리고 그것이 자동 생성 다국어 코드 benchmark의 난도 등가성 논의를 어떻게 이끄는지
코드 평가의 첫 질문은 누가 1등인가가 아닙니다. 문제는 과제가 어디서 왔는가입니다. benchmark가 모델에 의해 생성되고, 번역되고, 필터링된다면 점수는 더 이상 모델이 문제를 푼 결과만이 아닙니다. 문제를 만든 시스템의 산물이기도 합니다.
《AutoCodeBench》를 읽을 가치가 있는 이유는 자동 다국어 코드 benchmark의 어려운 문제를 드러내기 때문입니다. 언어 사이에서 “어려움”이 정말 동등하게 유지되는가입니다. Elixir 열이 중요한 것은 LLM이 Elixir를 가장 잘한다는 증거라서가 아니라, benchmark pipeline의 구조적 변수를 드러내기 때문입니다.
먼저 이 순위표가 무엇을 보여주는지
먼저 논문 원표를 직접 보는 편이 이해가 쉽다.
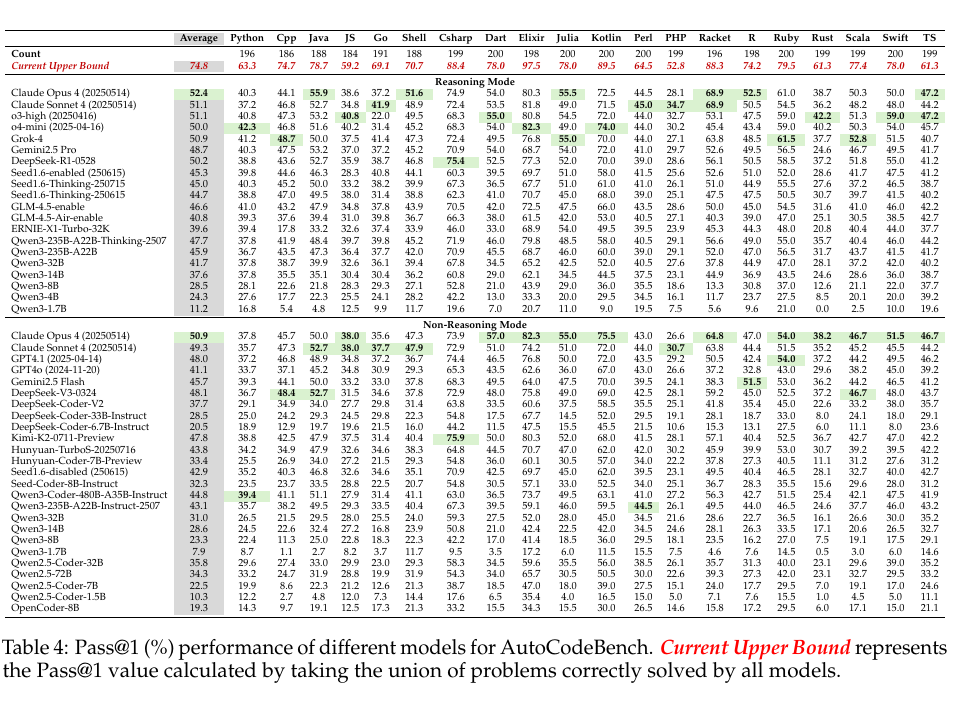
원문 Table 4에서는 각 행이 하나의 참가 대형 모델이고, 각 열이 하나의 프로그래밍 언어다.
둘이 만나는 칸의 숫자는 그 언어 문제를 그 모델에게 줬을 때, 첫 번째로 낸 답안만 보고 몇 문제가 한 번에 통과했는지를 뜻한다. 논문은 이 지표를 Pass@1이라고 부른다. 여기서 @1은 말 그대로 “한 번만 기회가 있다” 정도로 이해하면 된다.
맨 위에는 Current Upper Bound라는 특수한 행이 있다. 이 행은 특정 모델의 결과가 아니다. 참가한 모델들 중 어느 하나라도 맞힌 문제를 모두 합집합으로 모아 계산한 통과율이다. 즉 어떤 문제가 어떤 모델이든 한 번이라도 맞혔다면, 그 문제는 이 상한에 들어간다. 논문 표 주석에도 이 점이 명시돼 있다.
Elixir는 총 198문항이고, Current Upper Bound는 97.5다. 거칠게 계산하면 약 193개의 Elixir 문제가 적어도 한 모델에는 풀렸다는 뜻이다. 같은 행에서 Kotlin은 89.5, C#은 88.4, Racket은 88.3, Python은 63.3이다.
여기서 가장 쉽게 빠지는 함정이 있다. Elixir 97.5와 Python 63.3을 바로 이어서 “Elixir가 Python보다 대형 언어 모델에 더 적합하다”라고 쓰면 안 된다.
그건 엄밀한 결론이 아니다.
언어마다 문제의 출처도 다르고, 생성 방식도 다르며, 난도 필터링이 작동하는 방식도 같지 않을 수 있기 때문이다. 언어 열의 숫자만 보고 언어 자체의 우열을 말해 버리면 benchmark 결과를 과잉 해석하게 된다.
정말 물어야 할 질문은 따로 있다.
같은 모델들, 같은 평가 파이프라인 안에서 왜 Elixir 열은 이렇게 안정적으로 높은 위치에 머무는가?
이건 특정 모델 하나의 우연이 아니다
먼저 한 가지 설명을 지워 보자. 혹시 이것이 단지 Current Upper Bound라는 통계량의 성격 때문일 수도 있다. 여러 모델의 정답을 합집합으로 모으면 숫자가 올라가는 것은 당연하다.
그렇다면 개별 모델 행을 봐야 한다.
Claude Opus 4 추론 모드에서 Elixir는 80.3이고, C#은 74.9, Kotlin은 72.5다. Claude Sonnet 4 비추론 모드에서는 Elixir가 74.2, C#이 72.9, Kotlin이 72.0이다. DeepSeek-R1-0528 추론 모드에서는 Python이 38.8인데 Elixir는 77.3이다.
여기서 비교하고 있는 것은 “Claude 대 Elixir”가 아니다. Claude는 모델이고 Elixir는 언어다. 둘은 같은 차원 위에 있지 않다.
실제로 비교하는 것은 이것이다.
같은 모델을 기준으로 가로로 봤을 때, 언어별 성능이 어떻게 달라지는가.
Table 4를 행 단위로 가로로 훑어 보면, Elixir는 계속 높은 점수 쪽에 나타난다. 어떤 한 모델의 단발성 흔들림이 아니라, 여러 모델 결과에서 반복해서 나타나는 언어 열 현상이다.
그래서 문제는 leaderboard에서 언어별 열로 이동한다.
문제는 어떻게 만들어졌는가
이 현상을 이해하려면 AutoCodeBench의 생성 파이프라인으로 돌아가야 한다.
논문은 AutoCodeGen이라는 자동화 파이프라인을 제안한다. Stack-Edu 안의 실제 코드 조각에서 씨앗을 뽑고, 모델이 그것을 독립적으로 실행 가능한 완전한 풀이로 확장하도록 한 다음, 공개 테스트와 비공개 테스트 입력을 생성한다. 그 풀이와 테스트를 다국어 샌드박스에서 실행해 실제 출력을 얻고, 마지막에는 풀이와 테스트 함수로부터 역으로 문제 설명을 생성한다.
이 설계의 핵심은 테스트 출력이 모델이 상상해서 적은 값이 아니라는 점이다. 실제로 코드를 실행해서 나온 결과다.
바로 이 점 때문에 AutoCodeBench는 “모델에게 문제와 테스트를 직접 쓰게 한다”는 방식보다 더 믿을 만하다. 모델은 후보를 만들고, 샌드박스는 사실을 제공한다.
다만 20개 언어가 완전히 같은 방식으로 생성된 것은 아니다.
논문은 이 부분을 분명히 적고 있다. Python, C++, Shell, Java, JavaScript, Go의 6개 언어는 완전한 AutoCodeGen 파이프라인을 직접 사용한다. 나머지 14개 언어도 이론상 같은 흐름을 탈 수 있지만, 자원과 다양성이 부족해서 논문은 근사 언어 번역을 사용했다. Table 3에서 Elixir의 번역 경로는 Python → Elixir다.
여기서 아주 중요한 변수가 생긴다.
Elixir 문제는 Elixir 생태계의 원생 문제라기보다, Python 문제를 Elixir로 옮긴 문제일 가능성이 크다.
번역 자체가 문제라는 뜻은 아니다.
문제는 번역 이후에도 난도가 다른 언어와 같은 수준으로 유지되느냐는 점이다.
난도 필터에는 언어별 사각지대가 있다
AutoCodeGen에는 난도를 제어하는 장치가 있다.
각 문제에 대해 DeepSeek-Coder-V2-Lite로 10번 샘플링하고, 샌드박스에서 정답을 검증한다. 10번 모두 통과하면 그 문제는 너무 쉽다고 보고 버린다. 논문은 그런 문제는 평가 가치가 낮다고 본다.
이 논리는 인기 언어에서는 더 잘 작동한다.
필터링 모델이 Python, Java, C++에 익숙하다면, 10번 모두 맞히는 문제는 실제로 쉬운 문제일 가능성이 높다. 반대로 자꾸 틀리는 문제는 어느 정도 난도가 있을 가능성이 높다.
하지만 Elixir처럼 저자원 언어로 가면 상황이 복잡해진다.
논문 Section 3.3은 인기 언어와 저자원 언어를 따로 비교한다. 인기 언어 그룹은 Python, C++, Java, C#이고, 저자원 언어 그룹은 Racket, Shell, Elixir, TypeScript다. 결과는 이렇다. 인기 언어 그룹에서는 모델 평균 Pass@1 차이가 50.4에서 53.8로 상대적으로 작고, 저자원 언어 그룹에서는 45.3에서 62.0으로 훨씬 넓다.
논문은 이어서 중요한 단서를 하나 제시한다. 상위권 모델들이 저자원 언어에서 훨씬 더 잘 나오는 이유는, DeepSeek-Coder-V2-Lite가 저자원 언어에서 충분히 강하지 못해 쉬운 문제를 제대로 걸러내지 못했기 때문일 수 있다는 것이다.
이 문장은 꽤 중요하다.
논문이 직접 “Elixir 점수가 높은 건 문제가 쉬워서다”라고 말하는 것은 아니다. 하지만 아주 그럴듯한 기제 설명은 제공한다.
쉬운 문제를 걸러내는 데 쓰인 모델이 저자원 언어에서는 충분히 강하지 않을 수 있다. 그 결과 강한 모델에게는 그다지 어렵지 않은 문제들이 같은 강도로 걸러지지 않은 채 남았을 수 있다.
이 설명은 “대형 언어 모델이 Elixir를 특히 잘한다”는 설명보다 훨씬 더 안정적이다.
Elixir의 높은 점수는 단순한 언어 숙련도만이 아니라, 세 가지 요인이 동시에 겹친 결과일 수 있다.
첫째, 문제는 Python → Elixir의 근사 번역에서 왔다.
둘째, 난도 필터는 저자원 언어에서 인기 언어만큼 신뢰롭지 않을 수 있다.
셋째, 상위 모델과 필터링 모델 사이의 능력 차이가 저자원 언어에서 더 크게 드러난다.
이 세 가지를 함께 놓고 보면, 왜 Elixir 열이 유난히 밝게 보이는지 훨씬 자연스럽게 설명된다.
Lite 버전은 다른 방향의 증거를 준다
AutoCodeBench에는 AutoCodeBench-Lite라는 경량 버전도 있다.
Lite의 구성 방식은 또 다른 단서를 제공한다. 논문은 먼저 모든 모델의 풀이 결과를 모은 뒤, 각 문제가 몇 개 모델에 의해 풀리는지 기준으로 정렬한다. 두 개 미만의 모델만 푼 문제는 먼저 버리고, 남은 문제들 가운데서 통과 모델 수가 적은 것부터 약 1,500개를 고른다. 논문의 의도는 “최소한 어떤 모델은 풀지만, 여전히 모델 간 차이를 보여 주는 문제”를 남기는 데 있다.
전체 AutoCodeBench에서 Elixir 문제는 198개다.
Lite 버전으로 가면 Elixir는 61개만 남는다. 20개 언어 중에서도 가장 적은 쪽에 속한다. 이보다 적은 것은 JavaScript의 57개와 PHP의 60개뿐이다.
이 숫자 하나만으로 “Elixir 문제는 다 쉽다”를 증명할 수는 없다.
Lite에 들어가지 못하는 이유는 두 가지일 수 있기 때문이다. 너무 적은 수의 모델만 풀어서 첫 단계에서 제거됐을 수도 있고, 너무 많은 수의 모델이 풀어서 통과 수가 낮은 문제부터 뽑는 과정에서 뒤로 밀렸을 수도 있다.
하지만 Elixir의 Current Upper Bound가 97.5까지 올라가 있고, 많은 개별 모델 행에서도 Elixir 점수가 높다는 점을 함께 놓고 보면, Lite로 줄어드는 이 변화는 적어도 하나의 간접 신호는 제공한다.
전체 Elixir 문제 집합의 난도 분포는 다른 언어들과 완전히 같지 않을 가능성이 높다.
핵심은 바로 이 부분이다.
이 말은 Elixir 문제가 “잘못됐다”는 뜻도 아니고, AutoCodeBench가 “믿을 수 없다”는 뜻도 아니다.
자동 생성, 근사 번역, 모델 기반 필터링으로 benchmark를 만들 때, 생성 파이프라인 자체가 언어별 난도 분포를 바꿔 놓을 수 있다는 뜻이다.
더 은밀한 편향이 하나 더 있다
논문 Section 4.2는 모델 편향 문제도 다룬다.
전체 생성 파이프라인은 DeepSeek 계열 모델에 크게 의존한다. DeepSeek-V3-0324는 코드 생성을 담당하고, DeepSeek-R1-0528은 품질 검수를 담당하는 Critic 역할을 한다. 논문도 이 점이 DeepSeek 계열 모델에 유리한 편향을 줄 수 있다고 인정한다. 이를 완화하기 위해 쉬운 문제 필터링 단계에는 DeepSeek-Coder-V2-Lite를 넣어 일종의 “push-and-pull” 균형을 만들려고 했다.
더 중요한 점은, 정량 결과를 보면 이것이 단순히 “출제자가 유리하다”는 한 문장으로는 끝나지 않는다는 것이다.
Table 7의 단계별 결과를 보면 Critic 필터링 단계는 실제로 DeepSeek-R1-0528의 성능을 올려 준다. 하지만 o3와 Gemini 2.5 Pro의 상승 폭은 오히려 DeepSeek-V3-0324보다 더 크다. 논문의 최종 판단도 매우 절제돼 있다. 자동 파이프라인이 DeepSeek 계열에 유리한 편향을 줄 수는 있지만, 영향은 작아 보인다는 것이다.
이 부분은 Elixir와 똑같은 문제는 아니지만, 둘 다 같은 핵심을 가리킨다.
자동화된 benchmark는 중립적인 기계가 아니다.
누가 문제를 만들고, 누가 검수하고, 누가 쉬운 문제를 걸러내고, 어떤 언어는 원생 생성이고 어떤 언어는 번역 생성인지. 이런 모든 요소가 데이터 안에 흔적을 남긴다.
그리고 결국 그 흔적은 조용히 리더보드로 들어간다.
Elixir 97.5는 무엇을 말해 주는가
이 숫자가 뜻하지 않는 것은 “대형 언어 모델은 Elixir를 가장 잘한다”는 말이다.
또 “AutoCodeBench에는 문제가 있다”라고 쓰는 것도 맞지 않다.
더 정확한 문장은 이쪽에 가깝다.
AutoCodeBench는 자동 생성 다국어 benchmark의 핵심 난점을 드러낸다. 언어 간 난도 등가성은 겉보기보다 훨씬 어렵다.
표면만 보면 20개 언어가 균형 있게 배치돼 있다. 언어마다 대략 200개 문제다.
하지만 개수 균형이 곧 난도 등가성을 의미하지는 않는다.
Python 문제를 Elixir로 번역했을 때, 그것이 여전히 Elixir 생태계의 실제 문제를 대표하는가?
필터링 모델이 Python에서는 쉬운 문제를 잘 걷어 낸다면, Elixir에서도 같은 날카로움으로 걷어 낼 수 있는가?
샌드박스는 실행 결과를 검증할 수 있지만, 문제 설명, 언어 관습, 인터페이스 설계, 표준 라이브러리 사용 방식까지도 모든 언어에서 똑같이 자연스럽고 공정한가?
이 질문들은 총점 표에는 직접 나타나지 않는다.
하지만 Elixir 열은 그 질문들을 다시 표면으로 끌어올린다.
이 논문에서 정말 쓸 만한 부분
AutoCodeBench의 가치는 모델 순위를 매긴 것에만 있지 않다.
더 중요한 기여는 benchmark 생산 방식을 한 단계 앞으로 밀었다는 데 있다. 모델이 문제를 생성하고, 샌드박스가 출력을 검증하고, Critic이 품질을 점검하고, 반복 샘플링이 난도를 걸러낸다. 논문은 AutoCodeBench가 20개 프로그래밍 언어에 걸쳐 3,920개 문제와 37,777개 테스트 케이스를 포함하며, 더 어렵고 더 실용적이며 더 넓은 언어 범위를 갖는 코드 생성 평가셋을 목표로 한다고 분명히 말한다.
이 길은 앞으로도 계속 갈 가능성이 높다.
코드 평가는 본질적인 장점이 있기 때문이다. 코드는 실행할 수 있다. 과제 정의만 충분히 명확하다면 테스트 케이스로 정답을 검증할 수 있다. 글쓰기, 개방형 질의응답, 복잡한 추론과 비교하면, 코드는 “생성 → 실행 → 검증 → 필터링”의 폐쇄 루프를 만들기에 훨씬 적합하다.
하지만 Elixir 열은 자동화가 공짜가 아니라는 사실을 상기시킨다.
문제를 생성하는 모델은 자신이 익숙한 문제 구조를 집어넣는다.
문제를 번역하는 모델은 원천 언어의 과제 모양을 집어넣는다.
난도를 걸러내는 모델은 자기 언어 능력의 한계에 묶인다.
샌드박스는 실행 결과를 검증할 수 있지만, 문제 자체가 각 언어 생태계 안에서 똑같이 자연스럽고 똑같이 공정하다고 보장하지는 못한다.
그래서 앞으로의 코드 benchmark는 어떤 모델이 가장 높은 점수를 냈는가만 물어서는 안 된다. 이 질문도 함께 해야 한다.
- 이 문제들은 어떻게 생성됐는가?
- 어떤 언어는 원생 생성이고, 어떤 언어는 번역 생성인가?
- 난도 필터는 언어마다 같은 수준으로 강한가?
- 인간 검증은 어떤 언어를 덮고 있고, 어떤 언어는 빠져 있는가?
논문의 인간 검증은 Python, C++, Java, JavaScript, Go, Shell의 여섯 언어만 포함하며, 정확도는 87.6%다. Elixir는 이 인간 검증 언어 집합에 들어 있지 않다. 이 디테일 역시 번역 생성 언어의 품질과 난도 분포에 대해 더 촘촘한 후속 검증이 필요하다는 점을 보여 준다.
마지막 결론
Elixir가 이 표에서 이렇게 높게 나온다고 해서 곧바로 “대형 언어 모델이 Elixir를 가장 잘한다”라고 말할 수는 없다. 앞에서 본 변수들은 모두 실제로 작동한다. benchmark 생성 과정도 결과에 영향을 주고, 번역 경로도 영향을 주며, 저자원 언어에서 필터가 얼마나 잘 작동하는지도 결과에 영향을 준다.
그런데 그런 요소들을 다 감안하고도 Elixir 열은 따로 떼어 놓고 볼 만하다.
결국 남는 질문은 “이 점수를 어떻게 해석할까”가 아니라 왜 하필 Elixir냐는 것이다.
benchmark 생성 과정, 번역 경로, 난도 필터링 같은 조건을 다 테이블 위에 올려놓고도 Elixir가 여전히 이렇게 눈에 띈다면, Elixir는 적어도 계속 따라가 볼 만하다.
이걸 곧바로 “LLM이 Elixir에 강하다”는 증거로 쓰자는 뜻은 아니다. 다만 그 뒤에 정말로 더 들여다볼 가치가 있는 무언가가 있을 수 있다는 뜻이다.
그게 Elixir의 동시성 모델일 수도 있고, 추상화 방식일 수도 있고, 과제를 표현하는 방식과 언어 특성이 오늘날 대형 모델의 작동 방식과 더 깊게 맞닿아 있을 수도 있다.
OpenAI가 최근 오픈소스로 공개한 Symphony 프로젝트에도 Elixir 구현이 들어 있다.
이 방향은 왜 Elixir는 AI에 가장 잘 맞는 언어인가와도 연결된다.
댓글