AutoCodeBench: When LLMs Generate Code Benchmarks
Why the Elixir column stands out in AutoCodeBench, and how it opens up a discussion of difficulty equivalence in automatically generated multilingual code benchmarks
The first-principles question in code evaluation is not who ranks first. It is where the tasks came from. Once a benchmark is generated, translated, and filtered by models, the score is no longer only a product of models answering questions. It is also a product of the system that created the questions.
AutoCodeBench matters because it exposes a hard problem in automatic multilingual code benchmarks: whether “difficulty” remains equivalent across languages. The Elixir column matters not because it proves LLMs are best at Elixir, but because it exposes structural variables in the benchmark pipeline.
What This Ranking Table Is Showing
It helps to look at the original table first:
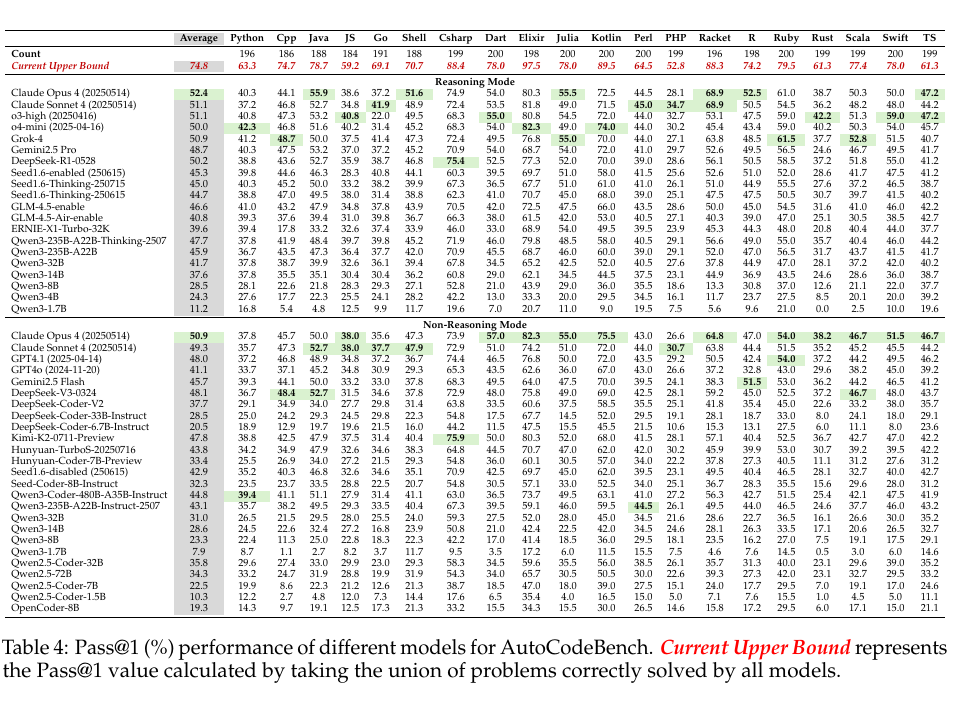
In the original Table 4, each row is one participating large model, and each column is one programming language.
The number at their intersection means: if you give that language’s tasks to that model and look only at its first submitted answer, what fraction of problems pass in one shot. The paper calls this metric Pass@1. You can read the @1 literally as “one chance.”
At the top there is a special row called Current Upper Bound. It does not belong to any one model. Instead, it is the pass rate after taking the union of all tasks solved by any participating model. If any model solved a given problem, that problem counts toward the upper bound. The paper states this explicitly in the table note.
Elixir has 198 problems, and its Current Upper Bound is 97.5. Roughly speaking, that means about 193 Elixir tasks were solved by at least one model. In the same row, Kotlin is 89.5, C# is 88.4, Racket is 88.3, and Python is 63.3.
There is an easy mistake to make here: you cannot directly turn Elixir 97.5 versus Python 63.3 into “Elixir is more suitable for large language models than Python.”
That would not be a rigorous conclusion.
Different languages have different task sources, different generation paths, and potentially different difficulty filtering effects. If you use language-column numbers to infer something about the inherent quality of the language itself, you push the benchmark interpretation too far.
The question that matters is this:
Given the same set of models and the same evaluation pipeline, why does the Elixir column stay near the top so consistently?
This Is Not a One-Model Accident
Let us first rule out one explanation: maybe this is just an artifact of the Current Upper Bound row. Once you take the union across many models, of course the number goes up.
So look at the individual model rows.
For Claude Opus 4 in reasoning mode, Elixir is 80.3, C# is 74.9, and Kotlin is 72.5. For Claude Sonnet 4 in non-reasoning mode, Elixir is 74.2, C# is 72.9, and Kotlin is 72.0. For DeepSeek-R1-0528 in reasoning mode, Python is 38.8 while Elixir is 77.3.
Notice what is being compared here. It is not “Claude versus Elixir.” Claude is a model, Elixir is a language; they are not even on the same axis.
What is being compared is:
For the same model, how does performance change across programming languages?
When you scan across Table 4 row by row, Elixir keeps appearing near the high end. This is not a one-model blip. It is a recurring language-column pattern across many models.
That moves the question from the leaderboard to the language columns.
Where the Problems Come From
To understand this pattern, you have to go back to the AutoCodeBench generation pipeline.
The paper proposes an automated pipeline called AutoCodeGen. It starts from real code snippets in Stack-Edu, lets a model evolve them into full standalone solutions, then generates public and private test inputs, runs the solutions and tests inside multilingual sandboxes to obtain real outputs, and finally works backward from the solution and tests to generate the problem statement.
The key design choice is this: the test outputs are not invented by the model. They are produced by actually executing code.
That is also why AutoCodeBench is more credible than a setup where a model simply makes up the problems and the tests. The model proposes candidates, but the sandbox provides facts.
Still, the 20 languages are not generated in exactly the same way.
The paper is explicit here. Python, C++, Shell, Java, JavaScript, and Go use the full AutoCodeGen pipeline directly. The other 14 languages could in principle do the same, but because of limited resources and insufficient diversity, the paper uses approximate language translation instead. In Table 3, the translation path for Elixir is Python → Elixir.
That introduces a crucial variable:
The Elixir tasks are likely not native Elixir-ecosystem tasks. They are Elixir tasks translated from Python tasks.
Translation itself is not the problem.
The real issue is whether the translated tasks still preserve the same difficulty level as tasks in other languages.
The Difficulty Filter Has a Language Blind Spot
AutoCodeGen has a difficulty-control mechanism.
For each problem, it samples 10 solutions from DeepSeek-Coder-V2-Lite and validates them in the sandbox. If all 10 pass, the problem is discarded, because the paper treats it as too easy to be useful for evaluation.
This logic is more reliable for popular languages.
If the filtering model is strong in Python, Java, and C++, then problems it solves perfectly 10 times are probably indeed too easy, and problems it fails are more likely to carry some real difficulty.
But once you move to a low-resource language like Elixir, the situation gets more complicated.
Section 3.3 of the paper explicitly compares popular languages with low-resource languages. The popular-language set is Python, C++, Java, and C#. The low-resource set is Racket, Shell, Elixir, and TypeScript. The result is that the average Pass@1 gap is smaller in the popular group, ranging from 50.4 to 53.8, while the low-resource group has a much wider range, from 45.3 to 62.0.
The paper then offers an important clue: top-tier models perform much better on low-resource languages, possibly because DeepSeek-Coder-V2-Lite is limited in those languages and struggles to filter out easy tasks.
That sentence matters a lot.
It does not directly say, “Elixir scores are high because the tasks are easy.” But it does provide a very plausible mechanism:
The model used to filter out easy problems may not be strong enough in low-resource languages. As a result, some problems that are not actually hard for stronger models were never filtered out with equal strictness.
That is a more stable explanation than “large language models are simply best at Elixir.”
Elixir’s high numbers may reflect not just language mastery, but the interaction of three things at once:
First, the tasks come from approximate Python → Elixir translation.
Second, the difficulty filter may be less reliable on low-resource languages than on popular ones.
Third, the capability gap between top models and the filtering model is amplified in low-resource languages.
Put those together, and it becomes much easier to understand why the Elixir column looks so unusually bright.
The Lite Version Offers Another Piece of Evidence
AutoCodeBench also has a smaller version called AutoCodeBench-Lite.
Its construction provides a side signal. The paper first collects the solving results of all models, then ranks tasks by how many models can solve them. Tasks solved by fewer than two models are discarded first. From the remaining pool, about 1,500 tasks are selected in ascending order of solve count. The idea is to keep tasks that at least some models can solve, but that still preserve discrimination between models.
In the full AutoCodeBench, Elixir has 198 tasks.
In the Lite version, Elixir drops to 61. Among the 20 languages, that is one of the smallest counts. Only JavaScript with 57 and PHP with 60 are lower.
That number alone does not prove that “Elixir tasks are easy.”
There are two possible reasons a task does not make it into Lite: too few models can solve it, so it gets filtered out in the first step; or too many models can solve it, so it gets pushed back when the paper selects tasks from low to high solve count.
But once you combine the 97.5 Current Upper Bound for Elixir with the fact that many individual model rows are strong on Elixir, the Lite shrinkage at least provides a side signal:
The difficulty distribution of the full Elixir task set is probably not fully equivalent to the distributions for other languages.
That is the actual point.
This is not a claim that the Elixir tasks are “broken.” It is not a claim that AutoCodeBench is “unreliable.”
It is a claim that when a benchmark is built through automatic generation, approximate translation, and model-based filtering, the generation pipeline itself can reshape difficulty distributions across languages.
There Is Another, More Subtle Bias
Section 4.2 of the paper also discusses model bias.
The overall generation pipeline relies heavily on DeepSeek-family models: DeepSeek-V3-0324 generates code, and DeepSeek-R1-0528 acts as the Critic for quality review. The paper openly acknowledges that this could create a favorable bias toward the DeepSeek family. To counterbalance that, it uses DeepSeek-Coder-V2-Lite during easy-problem filtering, trying to create a kind of push-and-pull equilibrium.
The more important point is that the paper’s quantitative analysis shows the story is not as simple as “whoever writes the exam benefits from it.”
In the stage-by-stage results of Table 7, the Critic filtering stage does improve DeepSeek-R1-0528, but the gains for o3 and Gemini 2.5 Pro are actually larger than the gain for DeepSeek-V3-0324. The paper’s final judgment stays measured: the automated pipeline may introduce favorable bias for the DeepSeek family, but the effect appears small.
This is not exactly the same problem as Elixir, but both point to the same core idea:
An automated benchmark is not a neutral machine.
Who generates the tasks, who reviews them, who filters out easy problems, which languages are generated natively, and which are produced through translation, all leave fingerprints in the data.
And in the end, those fingerprints quietly enter the leaderboard.
What Elixir 97.5 Actually Means
What it does not mean is that large language models are best at Elixir.
And it should not be framed as AutoCodeBench being flawed.
The more accurate statement is:
AutoCodeBench exposes a central difficulty in automatically generated multilingual benchmarks: difficulty equivalence across languages is much harder than it looks.
On the surface, the language distribution looks balanced. There are about 200 tasks per language.
But balanced counts do not imply equivalent difficulty.
If you translate a Python task into Elixir, does it still represent a real task from the Elixir ecosystem?
If the filtering model can remove easy tasks in Python, can it remove them with equal sharpness in Elixir?
The sandbox can validate execution outputs, but are the problem statements, language idioms, interface designs, and standard-library usage equally natural and equally fair in every language?
Those questions never appear directly in the total score.
But the Elixir column forces them back to the surface.
What This Paper Is Really Worth Writing About
The value of AutoCodeBench is not just that it ranks models.
Its more important contribution is that it pushes the production process of benchmarks one step forward: let models generate the tasks, let sandboxes verify outputs, let a Critic review quality, and let repeated sampling filter difficulty. The paper states clearly that AutoCodeBench contains 3,920 tasks and 37,777 test cases across 20 programming languages, with the goal of building a code-generation benchmark that is harder, more practical, and broader in language coverage.
This path will definitely continue.
Code evaluation has a natural advantage: code can be executed. Once the task is clearly defined, test cases can verify the answer. Compared with writing, open-ended question answering, or complex reasoning, code tasks are much better suited to a “generate → execute → verify → filter” loop.
But the Elixir column is a reminder that automation is not free.
Models that generate tasks will inject the problem structures they are most familiar with.
Models that translate tasks will inject the shape of the source language.
Models that filter difficulty are limited by their own language competence.
Sandboxes can verify execution results, but they cannot guarantee that the task feels equally natural and equally fair inside every programming-language ecosystem.
So future code benchmarks should not ask only which model scored highest. They should also ask:
- How were these tasks generated?
- Which languages are generated natively, and which are translated?
- Is the difficulty filter equally capable across languages?
- Which languages received human validation, and which did not?
The paper’s human validation covers only six languages: Python, C++, Java, JavaScript, Go, and Shell, with an accuracy of 87.6%. Elixir is not part of that human-validation set. That detail also suggests that translation-generated languages still need finer follow-up validation for both quality and difficulty distribution.
Final Takeaway
AutoCodeBench’s sharpest lesson is: the hard part of automatic benchmark generation is not creating tasks; it is keeping difficulty equivalent across languages.
Elixir’s high column does not justify the claim that LLMs are best at Elixir. Generation, translation, filtering, and human-validation coverage all affect the score. When tasks expand from Python into other languages, a language column mixes model ability, translation path, and the difficulty filter’s own competence.
That is exactly why the Elixir column should be tracked. It reminds us that a code benchmark is not a neutral container. Where tasks come from, how they are rewritten, and who filters them all enter the final number.
The next time you read a code benchmark, do not only ask which model has the higher Pass@1. Ask about the task supply chain: native generation or translation, which languages the difficulty filter handles well, and which languages received human validation. A benchmark earns interpretability only after it explains how its tasks came to exist.
Comments