《AutoCodeBench》:當大語言模型自動生成程式碼基準
AutoCodeBench 論文裡,為什麼 Elixir 這一語言欄值得注意,以及它如何引出自動生成多語言程式碼 benchmark 的難度等價討論
程式碼評測的第一性問題不是誰排第一,而是題目從哪裡來。只要 benchmark 由模型生成、翻譯、過濾,評測就不再只是「模型答題」,也是「模型出題系統」的產物。
《AutoCodeBench》 真正值得拆的地方,是自動生成多語言程式碼 benchmark 時,語言之間的「難」是否等價。Elixir 這一欄之所以值得看,不是因為它能證明大模型最擅長 Elixir,而是因為它暴露了評測生成流程裡的結構性變數。
先說這張排名表在講什麼
先看論文裡的原始表格:
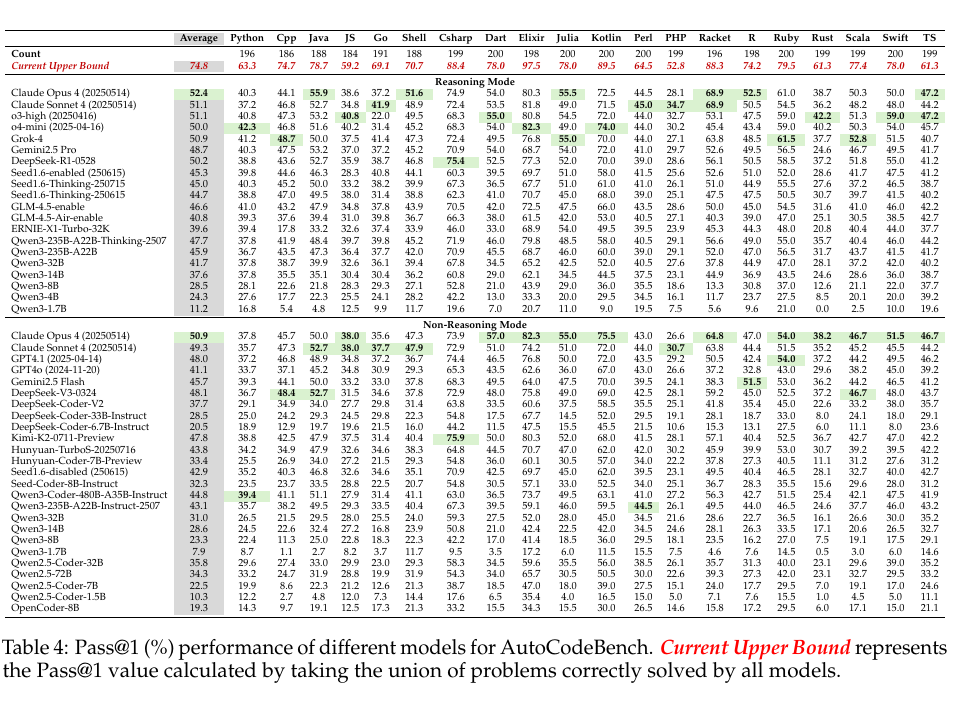
在原文 Table 4 裡,每一行是一家參評大模型,每一列是一種程式語言。
交叉處那個數字表示:把這一語言的題交給這個模型,只看它第一次交出的答案,最後有多少題能一次通過測試。論文把這個指標記作 Pass@1。這裡的 @1 可以直接理解成「只給一次機會」。
最上面有一行特殊的,叫 Current Upper Bound。它不屬於任何一個模型,而是把所有模型解對的題目取聯集之後算出來的通過率。只要某道題被任意一個參評模型做對,它就進入這個上界。論文表注明確寫了這一點。
Elixir 共 198 道題,Current Upper Bound 是 97.5。粗略折算,約 193 道 Elixir 題至少被一個模型解對。同一行裡,Kotlin 是 89.5,C# 是 88.4,Racket 是 88.3,Python 是 63.3。
這裡有個很容易踩的坑:不能把 Elixir 97.5 和 Python 63.3 直接寫成「Elixir 比 Python 更適合大模型」。
這不是一個嚴謹結論。
因為不同語言的題目來源不同,生成方式不同,難度過濾效果也可能不同。直接拿語言欄的數字去推導語言本體優劣,會把 benchmark 結果解釋過頭。
真正值得追問的是另一個問題:
同一批模型、同一套評測流程裡,為什麼 Elixir 這一語言欄會穩定處在高位?
這不是單個模型的偶然
先排除一種解釋:也許只是 Current Upper Bound 的統計特性。多個模型取聯集,數字自然會變高。
那就看單個模型行。
Claude Opus 4 推理模式下,Elixir 是 80.3,C# 是 74.9,Kotlin 是 72.5。Claude Sonnet 4 非推理模式下,Elixir 是 74.2,C# 是 72.9,Kotlin 是 72.0。DeepSeek-R1-0528 推理模式下,Python 是 38.8,Elixir 是 77.3。
注意,這裡比較的不是「Claude 和 Elixir」。Claude 是模型,Elixir 是語言,兩者不在同一維度。
這裡比較的是:
同一個模型,橫向看它在不同程式語言上的表現。
從 Table 4 橫著看,Elixir 經常出現在高分位置。它不是某一個模型的單點波動,而是多行模型結果裡反覆出現的語言欄現象。
這把問題從總榜拉到了語言欄。
題目是怎麼來的
要理解這個現象,得回到 AutoCodeBench 的生成流程。
論文提出了一套叫 AutoCodeGen 的自動化流程:從 Stack-Edu 裡的真實程式碼片段抽取種子,讓模型把它演化成可獨立執行的完整解法;再生成公開和私有測試輸入;把解法和測試輸入丟進多語言沙箱執行,得到真實輸出;最後根據解法和測試函式反向生成題目描述。
這個設計的關鍵是:測試輸出不是模型憑空寫出來的,而是程式實際跑出來的。
這也是 AutoCodeBench 比「讓模型直接編題編測試」更可信的地方。模型可以負責生成候選,沙箱負責給出事實。
但 20 種語言並不是完全用同一種方式生成的。
論文寫得很清楚:Python、C++、Shell、Java、JavaScript、Go 這 6 種語言直接使用完整 AutoCodeGen 流程;其餘 14 種語言雖然理論上也可以走同樣流程,但由於資料資源有限、多樣性不足,論文採用了近似語言翻譯。Table 3 裡,Elixir 的翻譯路徑是 Python → Elixir。
這就埋下一個關鍵變數:
Elixir 題目很可能不是 Elixir 生態裡的原生任務,而是從 Python 任務翻譯過去的 Elixir 任務。
翻譯本身不是問題。
問題在於:翻譯之後,題目難度是否還能和其他語言保持等價?
難度過濾器的語言盲區
AutoCodeGen 有一個難度控制機制。
它用 DeepSeek-Coder-V2-Lite 對每道題採樣 10 次,並用沙箱驗證答案。10 次全對的題會被丟掉,因為論文認為這類題太簡單,沒有評測價值。
這個邏輯在熱門語言上更容易成立。
如果過濾模型熟悉 Python、Java、C++,那麼它能 10 次做對的題,大概率確實偏簡單;它做不對的題,也更可能有一定難度。
但到了 Elixir 這樣的低資源語言,情況會變複雜。
論文 Section 3.3 專門比較了熱門語言和低資源語言。熱門語言組選的是 Python、C++、Java、C#;低資源語言組選的是 Racket、Shell、Elixir、TypeScript。結果是,熱門語言組裡模型平均 Pass@1 差距較小,範圍是 50.4 到 53.8;低資源語言組裡模型差距更大,範圍是 45.3 到 62.0。
論文隨後給出了一個解釋線索:頂級模型在低資源語言上表現顯著更好,可能是因為 DeepSeek-Coder-V2-Lite 在低資源語言上的能力有限,難以過濾掉簡單題。
這句話非常關鍵。
它沒有直接說「Elixir 高分就是因為題簡單」,但它提供了一個很合理的機制解釋:
用於過濾簡單題的模型,在低資源語言上可能不夠強。因此,一些對強模型來說並不難的題,沒有被同等強度地過濾掉。
這比「大模型最擅長 Elixir」解釋得更穩。
Elixir 的高分,可能不是單純來自模型對 Elixir 的語言掌握,而是同時受到三件事影響:
第一,題目來自 Python → Elixir 的近似翻譯。
第二,難度過濾器在低資源語言上可能不如在熱門語言上可靠。
第三,頂級模型和過濾模型之間的能力差,在低資源語言上被放大了。
這三件事疊在一起,就能解釋為什麼 Elixir 這一欄會特別亮眼。
Lite 版本裡還有一個側面證據
AutoCodeBench 還有一個精簡版,叫 AutoCodeBench-Lite。
Lite 的構造方式提供了一個側面證據:論文先收集所有模型的解題結果,再按每道題被多少模型解出來排序;通過模型少於 2 個的題先丟掉,然後從剩下的題裡按通過次數從低到高選擇約 1,500 道。論文這樣做,是為了保留那些「至少有模型能解,但仍有區分度」的題,讓模型之間的差距更清晰。
在完整 AutoCodeBench 裡,Elixir 有 198 道題。
到了 Lite 版本,Elixir 只剩 61 道。這個數量在 20 種語言裡屬於最低的一組,少於它的只有 JavaScript 的 57 和 PHP 的 60。
這個數字不能單獨證明「Elixir 題都簡單」。
因為題目沒有進入 Lite,可能有兩種原因:一種是太少模型能解,被第一步丟掉;另一種是太多模型能解,在按通過次數從低到高截取時排到了後面。
但結合 Elixir 的 Current Upper Bound 高達 97.5,以及很多單模型行裡 Elixir 得分靠前,這個 Lite 數量變化至少提供了一個側面訊號:
完整 Elixir 題集的難度分布,很可能和其他語言不完全等價。
這才是重點。
不是說 Elixir 題「有問題」,也不是說 AutoCodeBench「不可靠」。
而是說:當 benchmark 通過自動生成、近似翻譯和模型過濾構造時,不同語言之間的難度分布會被生成流程影響。
還有一層更隱蔽的偏差
論文 Section 4.2 還討論了模型偏差問題。
整個生成流程大量使用 DeepSeek 系列模型:DeepSeek-V3-0324 負責程式碼生成,DeepSeek-R1-0528 負責 Critic 品質審核。論文也承認,這可能對 DeepSeek 家族模型產生有利偏差。為了緩解這一點,作者在簡單題過濾階段使用 DeepSeek-Coder-V2-Lite,試圖形成一種「push-and-pull」的平衡機制。
更關鍵的是,論文的量化分析顯示,偏差並不是一句「誰出題誰佔便宜」就能解釋完。
在 Table 7 的階段性結果裡,Critic 過濾階段確實讓 DeepSeek-R1-0528 得到提升,但 o3 和 Gemini 2.5 Pro 的提升幅度反而比 DeepSeek-V3-0324 更大。論文最後的判斷也很克制:自動流程可能給 DeepSeek 家族帶來有利偏差,但影響較小。
這部分和 Elixir 不是同一個問題,但它們指向同一個核心:
自動化 benchmark 不是中立機器。
誰來生成題目,誰來審核題目,誰來過濾簡單題,哪些語言是原生生成,哪些語言是翻譯生成,都會在資料裡留下痕跡。
最後,這些痕跡會安靜地進入排行榜。
Elixir 97.5 到底說明了什麼
它說明的不是「大模型最擅長 Elixir」。
也不應該被寫成「AutoCodeBench 有問題」。
更準確的說法是:
AutoCodeBench 暴露了自動生成多語言 benchmark 的一個關鍵難題:語言之間的難度等價,遠比表面上更難。
表面上看,20 種語言分布均衡,每種語言大約 200 道題。
但分布均衡不等於難度等價。
一道 Python 任務翻譯成 Elixir 後,是否仍然代表 Elixir 生態裡的真實任務?
過濾模型在 Python 上能篩掉簡單題,在 Elixir 上是否也能篩得同樣乾淨?
沙箱能驗證程式輸出,但題目描述、語言習慣、介面設計、標準庫使用方式,是否也同樣自然、同樣公平?
這些問題都不會直接出現在總分裡。
但 Elixir 這一欄讓它們浮了出來。
這篇論文真正值得寫的地方
AutoCodeBench 的價值不只是給模型排了個名。
它更重要的貢獻,是把 benchmark 生產方式往前推了一步:讓模型生成題目,讓沙箱驗證輸出,讓 Critic 檢查品質,再用採樣過濾控制難度。論文也明確說,AutoCodeBench 包含 3,920 道題、37,777 個測試用例,覆蓋 20 種程式語言,目標是構造更困難、更實用、更多語言覆蓋的程式碼生成評測集。
這條路肯定會繼續走下去。
因為程式碼評測有一個天然優勢:程式碼可以執行。只要任務定義得足夠清楚,就可以透過測試用例驗證答案。相比寫作、開放問答、複雜推理,程式碼任務更適合形成「生成—執行—驗證—過濾」的閉環。
但 Elixir 這一欄提醒我們:自動化不是免費的。
模型生成題目,會帶入模型熟悉的問題結構。
模型翻譯題目,會帶入源語言的任務形狀。
模型過濾難度,會受自己的語言能力限制。
沙箱可以驗證執行結果,卻不能保證題目在每種語言生態裡都一樣自然、一樣公平。
所以,未來的程式碼評測不只要問哪個模型得分最高,還要問:
- 這套題是怎麼來的?
- 哪些語言是原生生成,哪些語言是翻譯生成?
- 難度過濾器在不同語言上的能力是否一致?
- 人工驗證覆蓋了哪些語言,又沒有覆蓋哪些語言?
論文裡的人類驗證只覆蓋了 Python、C++、Java、JavaScript、Go、Shell 六種語言,準確率為 87.6%;Elixir 並不在這組人工驗證語言裡。這個細節也說明,對翻譯生成語言的品質和難度分布,還需要更細的後續驗證。
最後的結論
AutoCodeBench 的釘子句是:自動生成 benchmark 的難點不是出題,而是讓不同語言裡的「難」保持等價。
Elixir 在表裡顯眼,不能直接推出「大型模型最擅長 Elixir」。benchmark 的生成、翻譯、過濾、人類驗證覆蓋範圍都會影響分數。尤其當題目由 Python 擴展到其他語言時,語言欄的分數就混合了模型能力、翻譯路徑和難度篩選能力。
但正因為這些變數都擺在檯面上,Elixir 這一欄才值得繼續追。它提醒我們,程式碼評測不是中立容器。任務從哪裡來、怎樣被改寫、由誰過濾,都會進入最終分數。
下次看程式碼 benchmark,不要只問哪個模型 Pass@1 更高。先問題目供應鏈:原生生成還是翻譯生成,難度過濾器在哪些語言上可靠,人工驗證覆蓋了哪些語言。一個 benchmark 只有先解釋清楚題目如何存在,分數才有解釋權。
評論